National Semi. PACE/INS8900 Test Boards
 In 1974 National Semiconductor introduced what is arguably the first 16-bit microprocessor (it had a 8-bit mode as well which was more efficient but could run 16-bits as well). This chip was made on a PMOS process and ran at 1.3MHz. In some ways it was ahead of its time, there wasn’t a ton of demand for a 16-bit processor at the time and interfacing to its PMOS architecture was…tricky.
In 1974 National Semiconductor introduced what is arguably the first 16-bit microprocessor (it had a 8-bit mode as well which was more efficient but could run 16-bits as well). This chip was made on a PMOS process and ran at 1.3MHz. In some ways it was ahead of its time, there wasn’t a ton of demand for a 16-bit processor at the time and interfacing to its PMOS architecture was…tricky.
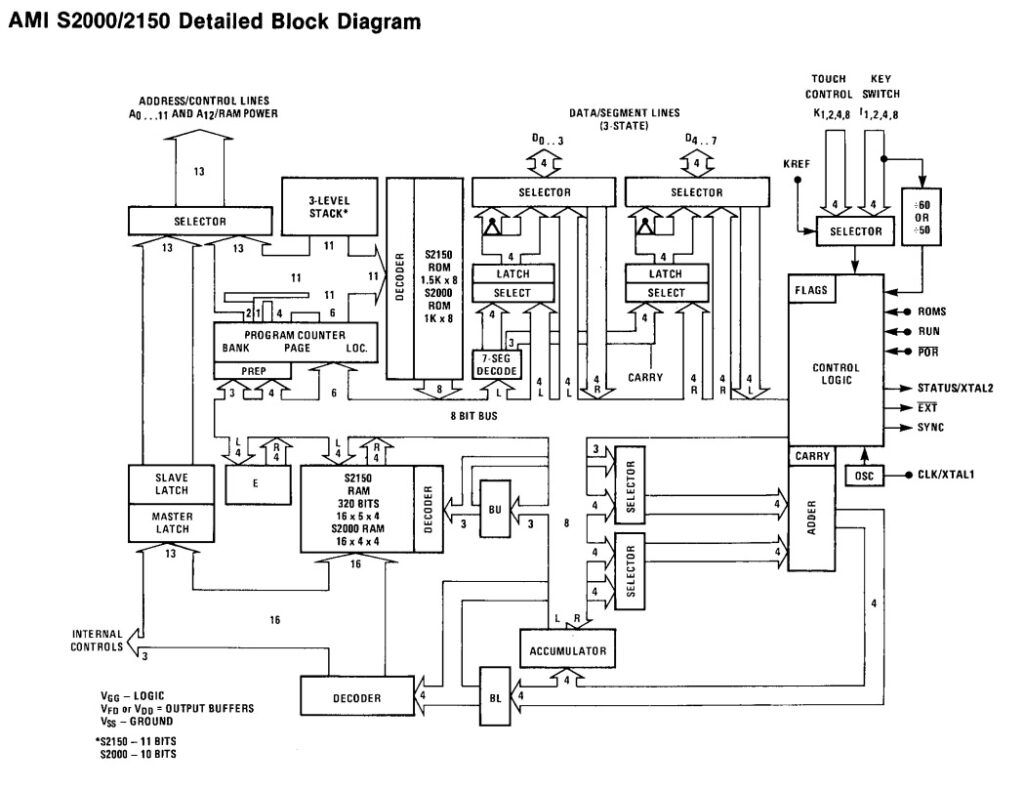
The PACE used -12V, +8V as well as +5V. It also required a high power 2 phase clock (the clock drove the internal logic). National was to use Signetics and Rockwell as second sources but neither ended up making chips. (this was a 2 way agreement, as National was to second source the 2650 for Signetics and the PPS-4/PPS-8 for Rockwell. The PACE had a 10 level 16-bit stack and 4 16-bit general purpose registers. It supported 46 instructions.

National Semi. IPC-16A-500D PACE 1977
The PACE found a very few design wins, mostly used in custom applications where its speed and 16-bit were useful. It was designed into a custom control system for a concrete batch plant, and later (in 1980) used by CERN in Switzerland to control a touch terminal used for particle accelerator experiments (specifically controlling the Modal terminal for the Super Proton Synchrotron). In this application its speed and its 16-bit capabilities were useful for the math functions needed. CERN eventually replaced it with the much easier to work with Motorola MC68000 (which had Euro sources available). A similar use was found by the Australians Dept of Defense to control a graphics terminal also used for physics experiments.

CERN Nodal Touch Terminal – Powered by PACE
In 1977 National converted the design to NMOS, which simplified its interfacing and increased the speed to 2MHz. This was the INS8900 which required -8VDC, 12V, and 5V but most importantly a normal single phase clock. The INS8900 also fixed a few bugs, some sources claim the INS8900 also added a NOP instruction, but this existed officially in the PACE as well (Opcode 5C00). In addition SFLG/PFLG 0000 can be used as a NOP on either processor.
The INS8900 was used in a very early multi-processor system designed by BRATO (British Rail Automatic Train Operation). This system was an early investigation of automating train/track control, and used three INS8900 CPUs to provide enough speed and redundancy to run the 3 programs deemed needed ( automatic driver, tachometer and safety supervisor). Each processor each program (so all 3 processors eventually run all 3 programs) and then the results are compared. The INS8900 was chosen over the TMS9900 because it utilized the bus much less (the TMS9900 user registers use external RAM, whereas the INS8900 has 4 general purpose internal registers), resulting in less chances of bus interference between the 3 processors. THe INS8900D was also used in some Sun (not the Sun Microsystems) Motor Testers, used in automotive repair sops in the early 1980’s.

INS8900D – 1979 – Early Production – Large black die cap

INS 8900D – 1985 – Late Production – Small Gold Die cap
These processors are a bit obscure, and as far as I can tell were not used in a ton of products. They do come up from time to time though, and The CPU Shack now has a test board design available for them.
The board was a challenge to build due to the PACE and the INS8900 having such different voltages and clocks, requiring separate Power Supply Panels to run each. These are now available for pre-order (we’re not thinking to generally stock these quite yet).

Price is $159 and includes free shipping worldwide. Pre order now and I should be able to ship in around 6 weeks.
If there is enough interest I will of course try to keep 1-2 in stock for that time you find a nice white/gold IPC-16 PACE CPU.
Posted in:
Boards and Systems, CPU of the Day