CPU of the Day: P.A. Semi PA6T PowerPC
When Apple bought P.A. Semi back in 2008 it was the beginning of the era of the iPhone, and their was much speculation as to why Apple was buying a company that made low power high performance PowerPC processors. Especially since the iPhone ran on ARM and the Mac had moved from PowerPC to x86.

P.A. Semi PA6T-1682M
P.A. Semi was started in 2003 by Daniel Dobberpuhl (who passed away in 2019). Dobberpuhl was one of the truly greats of microprocessor design, with a career starting at DEC on the T-11 and MicroVAX, before helping DEC transition to the Alpha RISC design (21064). It was Dobberpuhl who started the design center in Pal Alto (where P.A. Semi would later take its name from) that designed the DEC StrongARM processor. A processor that was later purchased by Intel and became the XScale line of ARM processors.
After Intel bought the StrongARM line, he then helped start SiByte, making MIPS based RISC CPUs, and continued to do so when SiByte was purchased by Broadcom. So when he started P.A. Semi it was less about PowerPC and more about RISC, PowerPC just happened to be the architecture they chose to use. The design team had extensive experience on a variety of CPU architectures, including SPARC, Itanium, and the early Opterons. You can see why this acquisition was so attractive to Apple.
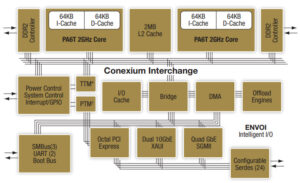
PA6T block diagram
In the few years (2003-2008) from when P.A. was founded to when Apple took them over, they did design, market, and sell a PowerPC processor line called PWRficient based on what they called the PA6T core. The PA6T-1682M was a Dual core PowerPC processor (the 13xxM was the single core version) with each core running at up to 2GHz with 64K of L1 Instruction cache and 64K of L1 Data cache. They were fab’d on a 65nm process by TI and ran at 1.1V. The L2 cache was scalable and shared amongst the cores. In the 1682M this was a 2M 8-way cache with ECC. One of the most useful features was their clock stepping. They could drop to 500MHz at only a few watts per core, and then back up to the full 2GHz in 25us.

AmigaOne X1000 (made by Aeon) PA6T-1682M
The PA6T was only on the marked for a few months (from the end of 2007 to April 2008) before Apple bought them for $300 million, but in this time P.A. Semi had numerous design wins. Amiga selected it for use in the AmigaOne X1000 computer. The AmigaOne did not hit market until 2011, which means that while P.A. Semi was bought and completely under control of Apple, they still continued to make, support, and supply their previous customers with the 1682M CPU. Certainly Amiga wouldn’t be big enough to push Apple to continue making a chip?
They were not, but others were, and the PA6T was such a great processor that it had been selected and designed in to many computer system used by US Defense contractors, and if anyone doesn’t like change, its Defense contractors, so with some prodding by the US Dept of Defense Apple continued to make (or rather have TI make) the PA6T processors. Curtis-Wright had designed the PA6T into their new CHAMP-AV5 DSP VME64 board, which was used for signals processing across numerous military applications. They also also used the PA6T (at 1.5GHz) in the VPX3-125 SBC. Themis computers, NEC, Mercury and others designed in the PA6T. Extreme Engineering, another maker of PA6T based boards, referred to the design as ‘ground breaking.’

Extreme Engineering XPedite8070 SBC
It would have been interesting to see what P.A. Semi could have achieved had they not been gobbled up by Apple. Clearly we see the results of the talent of the P.A. team in what Apple was able to accomplish with their A-series processors, but clearly P.A. had something special for the PowerPC architecture as well.
Posted in:
CPU of the Day